Over the past seven-ish years I’ve developed my own system for managing work from an executive perspective down to the individual contributor, and after some prompting from a friend (thanks MadHat!) I realized this might be helpful to others. Just to level set, the intent of this approach is to grow a full work management solution from nothing to the point where you can dynamically manage workloads and commitments, and to do so in a continuously evolving and improving way. As with anything agile… fail early, fail often, and go with what works for you and your teams. 🙂
To keep things simple I’m going to represent an organization with three levels. At the top is the Leader, who we’ll call Erica. Erica has two direct reports, who are in management positions, named Juan and Kiki. Juan and Kiki each have four direct reports, and through a quirk of nature all of Juan’s direct reports start with a “J” (James, Jules, Jasmine, and Jen) and all of Kiki’s start with a “K” (Karen, Kris, Katherine, and Karl).
I also need to highlight that you may read through this and think “I’ll just go straight to Phase X”… don’t do that. This process and approach is designed to educate on approach for both you and your team, and you’re going to find things that work well for you that don’t work well for me (and vice versa). Take the time, fail early, fail often, and build from it. I promise, it’s worth it in the end.
Phase Zero
Get Jira, if you don’t have it already (a free trial is available if you just want to play with all of this). The very first thing to do is to create a project, which brings us to a few key concepts in Jira that you need to grok quickly:
- Projects are collections of Issues.
- Issues are types of effort/work, such as “Stories”, “Tasks”, “Epics”, or “Bugs”. For the purposes of this process I only use “Stories” and “Epics”.
- Stories are single issues that describe a discrete and accomplishable objective.
- Epics are collections of Issues that represent a larger objective, and which can be broken down into smaller work items. The easiest way to remember this is that “many stories make an epic.”
- Boards are ways to visualize and interact with Issues.
Critically, boards can allow visualization and interaction across multiple projects. To give a quick example, let’s say that you want to implement a new customer management system. This is a large effort which could be well represented by a project, but there are many initiatives that will have to be completed to be successful. For example, you will need to establish requirements for the solution, but need to make sure that Legal, Sales, and Engineering all have input into them, and that you have prioritized which requirements are must-have ones versus which are desirable but not strictly required. You could conceive of this requirements capture as an epic with the following stories:
- Draft Requirements
- Legal Review of Requirements
- Sales Review of Requirements
- Engineering Review of Requirements
- Requirements Weighting
- Requirements Finalization
You might also need to follow your company’s funding approval processes, which might look like this as an epic with the following stories:
- Obtain Rough Estimate of Costs
- Enumerate Potential Benefits
- Rough Estimate of Benefits
- Build Business Case Presentation
- Schedule Funding Review Meeting
- Document Funding Approval
- Submit Funding Transfer Request
Each of these epics are composed of many smaller stories, and each epic is part of the overall project to implement the CMS system. If you are Erica, you probably don’t have time to worry about all of those individual stories/efforts… you just need to know if the funding has been approved or the requirements have been finalized. If you’re Juan or Kiki though you need to make sure your team is delivering. This is where agile Jira management can really deliver.
Remember when I said you need to create a project? Well, if you jumped ahead you may be looking at a lot of options wondering “which project type should I choose?” The answer is a Software Scrum project. That might seem counterintuitive but stick with me and we’ll get there. This will also create a default board, which is good.
Phase One: The Leadership Project
Now that you have a project, it’s time to start working. It can be tempting to do too much, so let’s break down a few simple things that will help you stay focused early on and scale as this process matures.
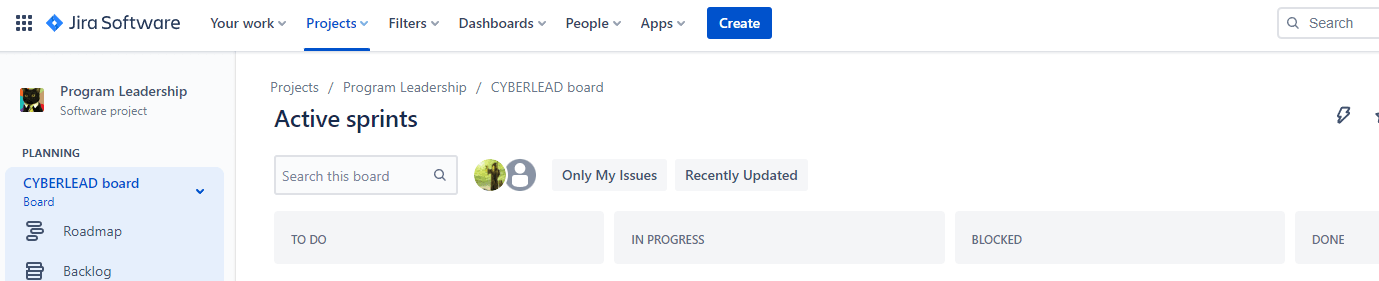
First up, you’re going to want four distinct buckets of work (called “statuses” in Jira):
- To Do is a built-in status that indicates work on a story has not yet been started, and is in the “To Do” status category
- In Progress is a built-in status that indicates work on a story has been started, and is in the “In Progress” status category
- Blocked is a status we’ll add to indicate that a story requires intervention/escalation, and should also be in the “In Progress” status category
- Done is a built-in status that indicates work on a story has been completed, and is in the “Done” status category
We use each of these statuses to track how a story progresses from intent through to completion. We also need to edit that default board that was created. All that we’re going to do is add a column (intuitively named “Blocked” between “In Progress” and “Done”) and assign the “Blocked” status to the “Blocked” column. This will set us up for moving between statuses.
The rules for how stories can move are called “transitions,” and the next step is to make a set of those rules, which is called a “workflow.” In short, workflows contain collections of transitions.
I use a very simple workflow:
- To Do can move to In Progress
- I call this the “Start Work” transition
- In Progress can move to To Do, Blocked, or Done
- I call the “In Progress” to “To Do” transition “Hold Work”
- I call the “In Progress” to “Blocked” transition “Escalate Problem”
- I call the “In Progress” to “Done” transition “Finish Work”
- Blocked can only move to In Progress
- I call this the “Resolve Problem” transition
That’s it! With that workflow created (start here) we’re now ready to get started with the hardest part of the entire process: building the initial backlog (a backlog is a collection of work that has been identified but not committed to being done).
At this stage the most important thing is to add in as much as you can think of… if you’d like to do it, add it (guidance here). If you know it’s something you’ll need to do in the next three months, add it. If you think you’ll never get to it, still add it. Quarterly reviews, projects, research about the latest Fortnite dance… be as granular or as broad as you’d like, because at this stage it’s all about quantity to kickstart the process. Don’t worry about setting any attributes, or details, or anything beyond just the “Summary” value and assigning it to somebody who will either work on it directly or be responsible for the team that works on it.
Phase Two: The Sprint
Now that we have a backlog with a pile of things in it, we need to create a sprint. A sprint is a time-based commitment to do some unit of work. We need to create one so we can start. Choose the next Monday morning and make that the day you start controlling what you and your team are going to do… and plan for that as a starting point. Go to your backlog, create a sprint, set a start/end date and time (I recommend two weeks to start), and fill the sprint with whatever stories you think you and your team can reasonably accomplish in that period of time. As a hint, naming your sprints based upon start or end date will make things easier in the long run (e.g. “Leadership 2022-10-10”).
Wait until the prophesized day and click the button to start the sprint. As you go through the sprint just move things each day to capture how they’re progressing, and as you identify new potential or committed work add it to the backlog (and the sprint if you’re going to work on it immediately).
At the end of the sprint take a look at what has happened and review the following questions:
- Did you run out of things to do?
- Overachiever or easy grader? 🙂 Add more for the next sprint!
- Did you have things that weren’t completed before the sprint ended?
- That’s normal! No need to panic, just learn from the experience.
- Did you have a LOT of things that weren’t completed before the sprint ended?
- If so, was it because there was a lot of change or because the estimate of work was too broad/unrealistic?
- Did you forget to update the stories until the end of the sprint?
- If so, it might be good to set a daily meeting of just ten minutes to ensure updates keep happening
- Did you have a lot of things join the sprint as it progressed that weren’t there when it started?
- If so, were they things that were known/foreseeable or were they unexpected interrupts to your plan?
Repeat this cycle (planning meeting, sprint execution, review) five times or so to get a good feel for how much work is getting done and continue building the backlog.
Phase Three: The Priority
Once you have a consistent flow of potential work going into your backlog, and a decent idea of how much work can be done each week, it’s time to adjust the approach. Take the time to go through the backlog and use the built-in “Priority” field to set every item as “Critical”, “High”, “Medium”, or “Low”. Again, these don’t have to be perfect. The goal at this stage is to identify priority.
Now start building the next sprint using only “Critical” items. That’s going to feel tough. In fact, you’re likely going to have many items that either are assessed as “things that can be fit in” or “things that really do need to be done.” Start adding in the review of whether or not the priority is accurate to the planning meetings, and recognize that this is a dynamic field; a story that is low priority this sprint may have escalated to critical priority by the next sprint, or a medium priority story may be overcome by events and degrade to a low priority story during the same time.
Once again, repeat this process for at least five sprints, and get comfortable with altering priorities continuously but using that data to drive work selection. I personally go through my backlogs about once a month just to see if the priorities there are still accurate. If you have hard committed dates where stories are due this is also the phase where I start adding those to stories for tracking purposes.
Phase Four: Getting Epic
It’s time to start grouping together stories into epics. Epics can be created in the backlog just like stories (see here). During planning sessions look at what themes/larger objectives need to be accomplished over the next two to four sprints, and what stories need to be completed to make that successful. For each of those larger objectives create an epic, and either associate existing stories to the epic or add new stories.
This phase is also a discovery phase, in which you should start enumerating “Template Epics” that you may have. For example, the requirements document mentioned earlier could instead be generalized to a template epic of publishing a document, with the following stories:
- Draft [NAME] document
- Internal team review of [NAME] document
- HR review of [NAME] document
- Legal review of [NAME] document
- OPTIONAL: Sales review of [NAME] document
- OPTIONAL: Communications plan for [NAME] document
- OPTIONAL: Execute communications plan for [NAME] document
- Publish [NAME] document
Identifying template epics like this allows you to do some really effective things like use CSV imports to create standard epics with known, repeatable tasks. Stay in this phase for an additional five or so sprints.
Phase Five: Pointers
Story points are a way of estimating the degree of effort required to complete a story. There are two primary schools of thought on this:
- Points represent difficulty, and people have varying rates of capability (e.g. Karen may be able to accomplish three points in the same time that Jasmine can accomplish two points).
- Points represent averaged time to complete assuming a random team member assignment for all stories
I tend to favor the second option because it allows for more consistency in creating template epics.
At this point it’s time to modify the process again. Now, each story in the backlog but especially in the sprint needs to have story points assigned. I use the convention that one point is one hour, both because that’s easy to understand and because there aren’t many meaningful stories that take less than one hour to complete in my experience. For the first two sprints focus just on getting all of the stories in the sprint and in the backlog established with points, and for the next three to five sprints add in the additional step of assessing during the review meeting how close those estimates were (and updating the remaining and related stories accordingly).
This is also a great time to update any template epics with points!
Phase Six: Forecasting
You’ve reached the stage where everything starts coming together… and now you can start forecasting. I calculate the following metric which I call the Resource Capacity Assessment (RCA) prior to each sprint:
RCA = (Total hours available in sprint per resource * Max Utility Rate) - (KTLO commitments)And those numbers are created as follows:
- Total hours available is the number of work hours that a resource will have during a sprint, after accounting for holidays, planned time off, etc. For a ten business day sprint with a half-day planned for a resource, for instance, this would be 76 hours.
- Max utility rate is the maximum amount of work you can reasonably expect to get out of someone, accounting for conversations, interactions, personal development time, etc. I typically use 0.65 as the value for this (assuming that roughly 1/3rd of all possible time is not available). Going above 0.75 typically creates a stressful environment and is not recommended.
- Keep The Lights On (KTLO) commitments is the amount of time that is committed on an ongoing basis to non-strategic/non-planned activities. For example, the KTLO commitments for a tier 1 security analyst might be 28 hours, but for a security architect it might be only 4 hours.
Each individual will have a separate RCA value, and their RCA value will change week by week (within a certain window). Now we add to the planning meeting the review of each individual’s assignments and RCA… and from there we can estimate out what can actually be done each sprint. We also add on a monthly basis or so a review of the max utility rate and KTLO commitments.
Phase Seven: Interrupts
At this point you should have a project that is consistently able to forecast efforts, track them to completion, and self-tune… but what about the dreaded work that wasn’t known when the sprint was being planned? This is the first and generally only time that I create a custom field, named “Interrupts” (a checkbox field that is either checked/true or not/false). This allows for two separate but important capabilities.
The first is a way to identify what work occurred during a sprint and the trend of interrupts occurring, to highlight types and frequency of work that are coming in during a sprint and not being accounted for either in the RCAs or the sprint planning. The second is the ability to look on a daily basis and say “if these interruptions are actioned during this sprint what work has to be moved to future sprints or otherwise negatively impacted to stay within the associated individual’s RCA”?
Again, run this for three to five sprints to build up the capability before moving on.
So you now have the ability to plan, prioritize, standardize, templatize, forecast, assess impacts/recommendations, and consistently report on all aspects of program execution. Not too bad! 🙂
Phase Eight: Splitsville
It’s finally time… the leadership team can start pulling away from the management team, and split things up. Create one new project for each manager, each of whom can return back to the start and begin taking their teams through the same processes. At this time I typically move the leadership project to a monthly cadence, so one leadership sprint covers two to four management sprints. This is also the time where I begin taking the leadership sprints out to six or more months of planned activities, because the process will support it. If they’re not already being used, the Jira content can now support direct reporting on project initiatives, template epics, interrupt rates, and backlog size/clearance cost estimation. The sky is the limit.
Plan Nine From Hermit’s (Head) Space
I hope this was useful. As with everything in this space I’m sure it will be updated and adjusted over the next few weeks as I realize that something could be better stated or more clearly conveyed, but if you have anything you’d like to see or know more about, or if more explicit “how to do thing” is needed please let me know on Twitter. Thanks!


Leave a comment